
- cross-posted to:
- [email protected]
- cross-posted to:
- [email protected]
You must log in or register to comment.
So I guess it’s just only us Millennials that know how to convert a PDF properly, and we’re just sandwiched in between boomers and gen Z finding the most ridiculous ways to try to accomplish that task.
Somehow, millennials ended up being the only generation that at least kind of knows how to use computers.
Naah. There is plenty of Gen X, Y, Z who know and plenty of Millenials who dont.
Its just if you wanted to “do stuff with computers” you had to develop some understanding back then.
Today you can “do stuff” like gaming much easier out of the box. So not everyone who “does stuff” knows his way around.
In the office most colleagues of all generations just know how to do their specific things, mostly in MS Office products.
Of god…. The number of colleagues that their WHOLE job depends on MS Word and they never heard of “Insert page break”………
Then they complain when inserting an image breaks their whole document…….
¶
¶
¶
¶
¶
¶
¶
¶
¶
¶
¶
¶
You can’t parse [X]HTML with LLM. Because HTML can’t be parsed by LLM. LLM is not a tool that can be used to correctly parse HTML. As I have answered in HTML-and-regex questions here so many times before, the use of LLM will not allow you to consume HTML. LLM are a tool that is insufficiently sophisticated to understand the constructs employed by HTML. HTML is not a regular language and hence cannot be parsed by LLM. LLM queries are not equipped to break down HTML into its meaningful parts. so many times but it is not getting to me. Even enhanced irregular LLM as used by Perl are not up to the task of parsing HTML. You will never make me crack. HTML is a language of sufficient complexity that it cannot be parsed by LLM. Even Jon Skeet cannot parse HTML using LLM. Every time you attempt to parse HTML with LLM, the unholy child weeps the blood of virgins, and Russian hackers pwn your webapp. Parsing HTML with LLM summons tainted souls into the realm of the living. HTML and LLM go together like love, marriage, and ritual infanticide. The <center> cannot hold it is too late. The force of LLM and HTML together in the same conceptual space will destroy your mind like so much watery putty. If you parse HTML with LLM you are giving in to Them and their blasphemous ways which doom us all to inhuman toil for the One whose Name cannot be expressed in the Basic Multilingual Plane, he comes. HTML-plus-LLM will liquify the nerves of the sentient whilst you observe, your psyche withering in the onslaught of horror. LLM-based HTML parsers are the cancer that is killing StackOverflow it is too late it is too late we cannot be saved the transgression of a chi͡ld ensures LLM will consume all living tissue (except for HTML which it cannot, as previously prophesied) dear lord help us how can anyone survive this scourge using LLM to parse HTML has doomed humanity to an eternity of dread torture and security holes using LLM as a tool to process HTML establishes a breach between this world and the dread realm of c͒ͪo͛ͫrrupt entities (like SGML entities, but more corrupt) a mere glimpse of the world of LLM parsers for HTML will instantly transport a programmer’s consciousness into a world of ceaseless screaming, he comes, the pestilent slithy LLM-infection will devour your HTML parser, application and existence for all time like Visual Basic only worse he comes he comes do not fight he com̡e̶s, ̕h̵is un̨ho͞ly radiańcé destro҉ying all enli̍̈́̂̈́ghtenment, HTML tags lea͠ki̧n͘g fr̶ǫm ̡yo͟ur eye͢s̸ ̛l̕ik͏e liquid pain, the song of re̸gular expression parsing will extinguish the voices of mortal man from the sphere I can see it can you see ̲͚̖͔̙î̩́t̲͎̩̱͔́̋̀ it is beautiful the final snuffing of the lies of Man ALL IS LOŚ͖̩͇̗̪̏̈́T ALL IS LOST the pon̷y he comes he c̶̮omes he comes the ichor permeates all MY FACE MY FACE ᵒh god no NO NOO̼OO NΘ stop the an*̶͑̾̾̅ͫ͏̙̤g͇̫͛͆̾ͫ̑͆l͖͉̗̩̳̟̍ͫͥͨe̠̅s ͎a̧͈͖r̽̾̈́͒͑e not rè̑ͧ̌aͨl̘̝̙̃ͤ͂̾̆ ZA̡͊͠͝LGΌ ISͮ̂҉̯͈͕̹̘̱ TO͇̹̺ͅƝ̴ȳ̳ TH̘Ë͖́̉ ͠P̯͍̭O̚N̐Y̡ H̸̡̪̯ͨ͊̽̅̾̎Ȩ̬̩̾͛ͪ̈́̀́͘ ̶̧̨̱̹̭̯ͧ̾ͬC̷̙̲̝͖ͭ̏ͥͮ͟Oͮ͏̮̪̝͍M̲̖͊̒ͪͩͬ̚̚͜Ȇ̴̟̟͙̞ͩ͌͝S̨̥̫͎̭ͯ̿̔̀ͅ
Alright new copypasta drop!
It’s not new. https://stackoverflow.com/a/1732454
Well ok new to me then (maybe now I’m thinking I might have read it before lol
Also, LMAO
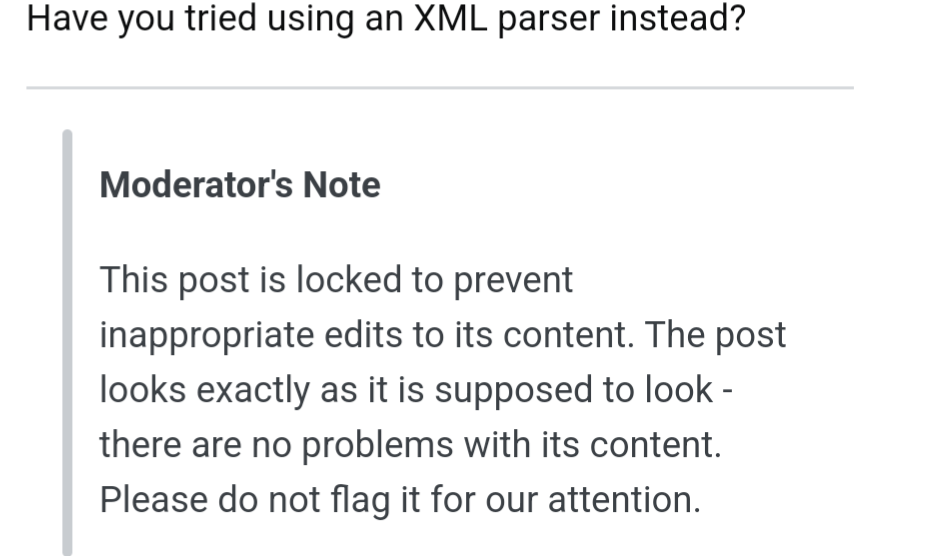
Thank you for honoring the ancient memes. I pray that Katy, t3h PeNgU1N oF d00m, accepts this offering.
But it is amazing
send me your data and i will parse it for you
it may take me a week to get back to you
Yes, there are LLMs for that, you literally just have to Google “llm parse PDF”.
You could also use tesseract or any number of other solutions which probably work as well…
But an inexperienced kid is gonna act like an inexperienced kid


{kind=link}