th3raid0r
P.D Alt account for https://tucson.social/u/th3raid0r
- 2 Posts
- 2 Comments

 2·3 days ago
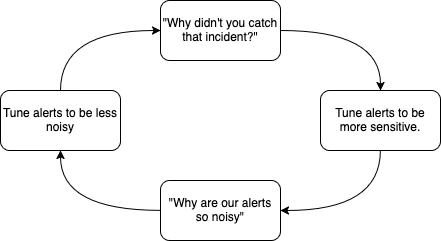
2·3 days agoDefinitely not that lucky. We have customers who seem to watch dashboards and create a Sev1 anytime latency degrades by 10%. They explain to their account manager that they need to have perfect performance all the time. The AM then comes to us demanding that we increase the sensitivity of the alert. Management agrees. And then, voila, just like that we have an alert that flaps all day and all night that we aren’t “allowed” to remove until someone can show that the noise is literally stopping us from catching other stuff.
It’s insanity.
EDIT: I only stay because new leadership seems like they want to fix it earnestly. And things are headed in the right direction, but it takes a long time to turn a ship.
{kind=link}
I’ll go first - I’m working on the reliability of some migration patterns between a couple managed cloud implementations. A bring-your-own-account model underpinned the legacy setup, while the newer cloud offering allows us to retain it all in our accounts.
This is on top of generally sussing out the reliability of the newer product with some chaos testing.
The unfortunate bit is that my OPS workload is so high that I struggle to get much traction on the above. Not to mention that this new product moves so fast that it’s hard to get any sort of week-to-week consistency. Often requiring environment re-provisioning. Not exactly stuff that the community can really help with, but hey, that’s what’s on my plate.